



The rise of artificial intelligence (AI) image generation tools brings major challenges in distinguishing between authentic and synthetic content. While these technologies are pushing the boundaries of creativity and visual production, they are also leading to the proliferation of manipulated images that are difficult for the human eye to identify.
In a recent study, 69% of respondents said they were concerned about the use of “deepfakes” which are videos faked by an AI to make people believe someone is saying or doing something they have neither done nor said. This phenomenon presents crucial integrity and security issues, as well as economic, cultural and political risks. For instance, during the 2024 French parliamentary elections, some political groups used AI-generated images to try to manipulate public opinion.
AI is based on a fundamental element: the quality of the data used to train models. A detection model is only effective if the data it is fed with is accurate, well-labelled and representative of the diversity of images, whether they are synthetic or not.
Identifying AI-generated images
While impressive, image generators using AI are not without errors. Their ability to create realistic images is often affected by subtle errors, such as distortions or visual artefacts (technical defects or anomalies in the compression of an image). Artificial intelligence and forensic analysis (the study of digital traces, metadata and visual inconsistencies) make it possible to identify these inconsistencies. AI can detect irregular structures, such as unwanted repetitions, imperfections in textures or clean elements in an image (hands, clothes, shadows), providing an effective method of detection.
The importance of transfer learning and data quality
Encouraged by global trends and the accessibility of artificial image creation, the companies behind these tools have found themselves in a frantic race to meet ever-increasing demand. However, this acceleration creates a major technical challenge: detection methods quickly become obsolete as image generators evolve. Faced with this problem, the use of transfer learning, which consists of reusing existing models and adapting them, could be a strategic solution. This enables us to capitalise on a solid knowledge base and accelerate new detection processes.
AI is based on a fundamental element: the quality of the data used to train models. A detection model is only effective if the data it is fed with is accurate, well-labelled and representative of the diversity of images, whether they are synthetic or not. Biased or poorly annotated data could compromise the accuracy of the model, leading to an increase in false positives and false negatives.
The cut-out method
Contrary to general approaches, the cut-out method allows specific areas of an image to be isolated and analysed. This specific segmentation makes it easier to identify recurring patterns or distinctive elements inherent to each visual. Nowadays, analysing an image as a whole is rarely the best solution: it can blur essential details in a vast flow of information, making interpretation less precise.
So how does it work? The successive cut analysis method is based on a 91% efficient Deep Learning model using Xception, which detects anomalies progressively by creating indexes (Fig 1). The image is first evaluated globally by the model; a “True” prediction means that the model has considered the image as real, and a “False” prediction means that the model has considered the image as generated by AI.

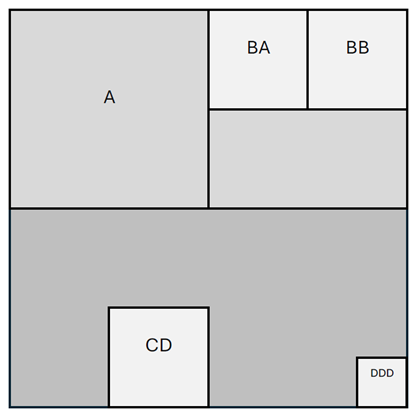


Index cut-out method & Cut-out levels – A(L1);BA,BB(L2);DDD(L3)
Then, in the case of a “False” prediction, it is subdivided into four equal parts, each being re-evaluated. This process is repeated up to three levels (Fig. 2), fine-tuning the analysis on critical areas, as only predictions with a confidence level of at least 90% are retained. After the screening process, the image is reconstructed, highlighting the areas that are tagged as “False”.




Highlighted images for 90% threshold
This is the first step of a more global approach aimed at building up a large corpus of high-quality labelled sub-images. The output will be used to train other models that are even more precise because they focus directly on images’ patterns and elements. It offers one key advantage: it precisely targets the weaknesses of the generation system by identifying poorly-learned patterns, making detection even more robust.
On a corpus of approximately 1,000 fake images, the results reveal that some elements occur frequently. Hair, clothes, eyes and lips are the categories most often identified as fake by the model for images classified as “Person”. These elements are complex to generate because of their high variability: hair has a multitude of textures and movements, clothes have various folds and patterns, and eyes and lips change in shape, expression and lighting. It enables better targeting of the weaknesses of AI image generators, refining training and improving detection accuracy.
As with any technological revolution, establishing a clear legal and ethical framework is essential in order to anticipate and limit potential abuses, thereby guaranteeing responsible and controlled innovation.
What’s next?
Even if these techniques now offer satisfactory results for improving model detection and training, they remain temporary. Like any analysis method, they can be bypassed once understood, making constant development necessary. Other approaches are emerging and seem promising. In particular, the use of asymmetric cryptography applied to images or digital fingerprints enables visual content to be traced and authenticated. However, as they require complex infrastructures and costly large-scale deployments, these new methods are designed for large companies, media, governments and institutions rather than individuals. These players are the main targets of the above-mentioned threats of disinformation, image manipulation or massive falsification.
More globally, these technologies are part of a dynamic in which artificial intelligence is redefining our interactions with information and digital creation. As with any technological revolution, establishing a clear legal and ethical framework is essential in order to anticipate and limit potential abuses, thereby guaranteeing responsible and controlled innovation. But for now, it is important to have tools that help us maintain the distinction between real and AI-generated.
This article is based on the author’s thesis as part of the Master of Science in Big Data Business Analytics at ESCP Business School.